Introducing Navigator
By the Yutori team on November 19, 2025

31 years ago, the modern web era began with the release of Netscape Navigator.
Today we're introducing Yutori Navigator — a state-of-the-art web agent that autonomously navigates websites on its own cloud browser to complete everyday tasks for you — available via our API.
Sign up here to get access.
Navigator handles a wide range of web tasks — checking availability, comparing prices, filling out forms, making reservations, ordering food, and completing purchases — with pareto-domination over previous models on accuracy, latency, and cost.
Navigator is powered by Yutori n11 — a pixels-to-actions2 LLM initialized from Qwen3-VL and trained via mid-training, supervised fine-tuning, and reinforcement learning (RL). During RL, n1 is not only trained on simulated web environments, but also on direct interactions with live websites. This uniquely allows n1 to learn the dynamics of real web environments and provides a scalable path for continuous improvement in the real world.
Navigator sets a new state of the art on browser-use benchmarks: 78.7% success rate on Online-Mind2Web3 and 83.4% on Navi-Bench, a new benchmark we are introducing. It also demonstrates strong real-world performance in Scouts, our consumer-facing web monitoring product, outperforming other computer-use models.
In addition to being the most effective, Navigator is also the most efficient agent, with per step latency4 that is 3.3x, 2.7x, and 2.0x faster than Claude 4.5, Gemini 2.55, and Claude 4.0 respectively.
Navigator is now available via our API. Sign up here to start using it.
Table of Contents
Evaluations
Online-Mind2Web
Online-Mind2Web6 is an open benchmark designed to evaluate the real-world performance of web agents on live websites, featuring 300 tasks across 136 popular sites in diverse domains.
We report both human evaluation results from Halluminate and auto-evaluation results from WebJudge, the official Online-Mind2Web evaluator.
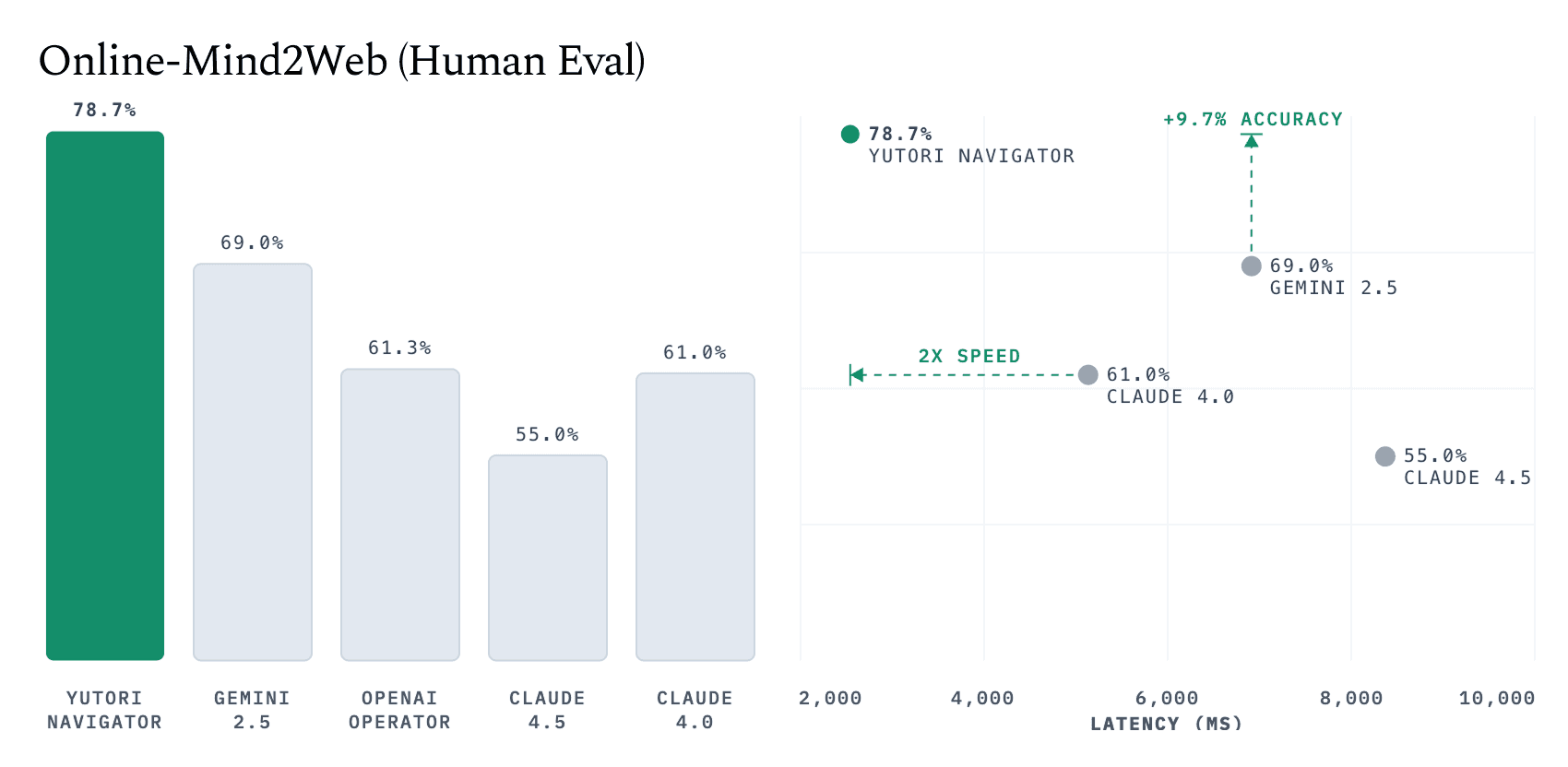
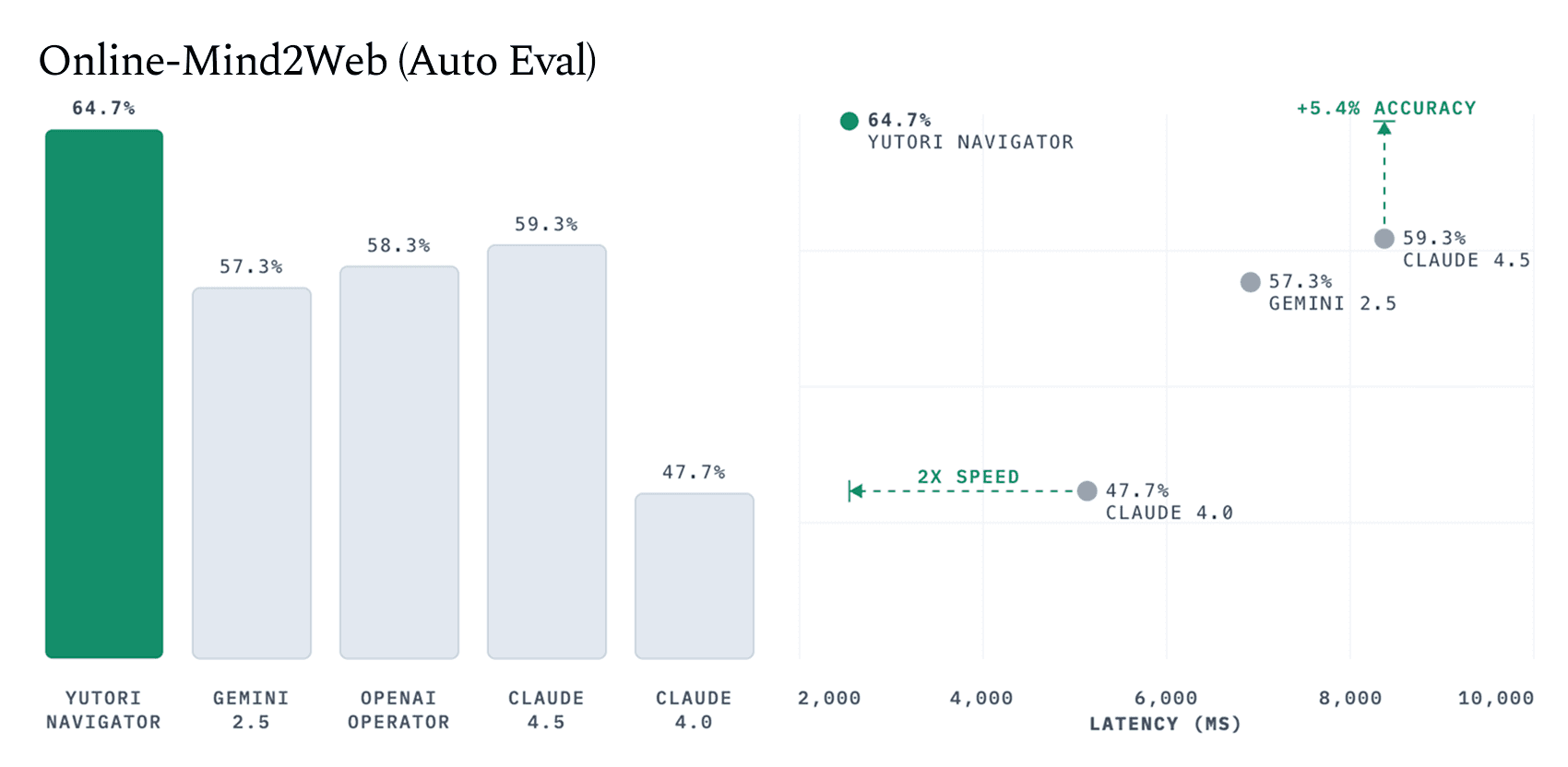
Figure 1. Navigator sets a new state of the art on Online-Mind2Web for both human and auto evaluation, while being the most efficient.
Navigator sets a new state of the art on Online-Mind2Web with 78.7% human-evaluation accuracy, far exceeding prior results from Gemini 2.55 (69.0%)3, OpenAI Operator (61.3%)3, Claude 4.0 (61.0%)7, and Claude 4.5 (55.0%)7. It also achieves the highest auto-evaluation performance of 64.7%, outperforming Gemini 2.5 (57.3%)3, OpenAI Operator (58.3%)3, Claude 4.0 (47.7%)8, and Claude 4.5 (59.3%)8.
Navigator also establishes a new pareto-frontier over previous models — making strict improvements in both accuracy9 and per-step latency10.
Navi-Bench
While Online-Mind2Web provides a wide coverage of websites, it relies on LLM-as-a-judge. Such auto-evaluators generally require human verification, which limits rapid iterations for model development.
Thus, we built Navi-Bench in collaboration with Halluminate — a benchmark designed to reliably evaluate web agents on everyday tasks directly on real websites, without humans in the loop.
Fundamentally, Navi-Bench relies on two key observations:
- There exists a generator-verifier gap, i.e. it is typically easier to verify that the agent has successfully reached certain website states than for the agent to generate the sequence of actions to reach them, and
- Agents need to generalize and scale to the web, verifiers do not.
Consider the task "Check on OpenTable if the Four Kings restaurant is available for dinner next Wednesday". This requires the agent to search for the restaurant, set the correct date/time, and then read the availability information from the page. A verifier for this task is a simple Javascript function that extracts relevant variables (selected date, selected time, etc.) from the web page DOM as the agent navigates and compares it to the desired state for this task. Note that while relying on DOM to build agents does not generalize2 or scale, relying on DOM to build deterministic and accurate verifiers for specific tasks works because it doesn't need to generalize; the skills learned by the agent do.
In Navi-Bench v1, we publish 100 tasks across 5 real websites: Apartments, Craigslist, OpenTable, Resy, and Google Flights. Please check out the dataset on Hugging Face and the Python SDK on GitHub.
Apartments.com
Find 2-3 bedroom apartments under $6800 in SoHo and nearby neighborhoods.
Craigslist
Search for 1-bedroom lofts in San Francisco under $3500/month.
Google Flights
Find Business class flights from Miami to Palma de Mallorca for March 2026.
OpenTable
Check New Year's Eve availability at The Little Door for 2 guests.
Resy
Check availability at Charlie Bird in New York for November 18 at 7 PM.
Navigator demonstrations on Navi-Bench websites.
Experiments on web tasks (e.g. checking restaurant availability) are difficult to compare because the web is dynamic (restaurant availability changes) and some tasks become infeasible (e.g. queries about past availability cannot be answered). Sometimes, realistic tasks are stated in a way where the task specification changes based on when the task is run (e.g., queries about availability tomorrow). Existing web benchmarks have settled on a particularly egregious configuration e.g., "Does this restaurant have availability on Aug 1, 2025?". The answer will change based on when the query is run, you can't check availability on a past date, and real users don't often specify tasks in this way. This causes a steady degradation in benchmark quality and different experiments remain incomparable. In Navi-Bench, we introduce a dynamic task configuration that renders the agent query and instantiates the corresponding success criteria when the experiment is run. This ensures that the evaluation reflects a current, valid real-world scenario.
Navi-Bench shares the same dataset format with Westworld — a benchmark from Halluminate featuring five simulated environments for e-commerce and travel tasks. This allows both benchmarks to be combined for evaluation. Furthermore, we intentionally created the tasks for real Google Flights similar to those of the corresponding simulated environment in Westworld (Noodle Flights), which allows us to study the sim-to-real gap for this domain.
Navi-Bench v1 (%)
| Model | Apartments | Craigslist | OpenTable | Resy | Google Flights | Average |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 46.3 | 36.3 | 43.2 | 65.0 | 73.8 | 52.9 |
| Claude Sonnet 4.0 | 36.7 | 21.7 | 78.3 | 73.3 | 78.3 | 57.7 |
| Claude Sonnet 4.5 | 76.7 | 56.7 | 66.1 | 83.3 | 88.3 | 74.2 |
| Yutori Navigator | 88.3 | 71.7 | 83.6 | 88.3 | 85.0 | 83.4 |
Halluminate Westworld (%)
| Model | Azora | Good Buy | Megamart | Travelpedia | Noodle Flights | Average |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 52.5 | 73.8 | 23.8 | 57.5 | 66.3 | 54.8 |
| Claude Sonnet 4.0 | 38.3 | 31.7 | 28.3 | 90.0 | 73.3 | 52.3 |
| Claude Sonnet 4.5 | 63.3 | 30.0 | 71.7 | 88.3 | 85.0 | 67.7 |
| Yutori Navigator | 91.7 | 73.3 | 100.0 | 83.3 | 81.7 | 86.0 |
On average, Navigator outperformed the other models by 9.2% on Navi-Bench v1 and 18.3% on Westworld. It also achieved the best success rate on most websites, including a perfect score on Megamart. This suggests that our model training system can effectively improve model reliability, and we may want to keep evolving the benchmarks to be even more challenging.
Furthermore, we can see that the results on Google Flights and Noodle Flights are highly correlated across different models. In the Reinforcement Learning section below, we show that by training with Noodle Flights, the model achieved similar improvements on both the real Google Flights and the simulated Noodle Flights. These observations suggest that the Halluminate Noodle Flights website has minimal sim-to-real gaps.
Real-world Evaluation in Scouts
Scouts monitor the web for anything a user may care about. This is fundamentally an information-seeking problem complicated by the realities of the web — data may not exist yet, may appear unpredictably, and may change quickly once it does. Accessing that information often requires direct interaction with websites. Evaluating computer-use agents in Scouts reveals how they perform in the wild, in the hands of users, outside controlled benchmarks.
We conducted human-preference evaluations11 to measure:
- Outcome quality - Whether the model retrieves the correct information, cites correct source pages, acknowledges when the results only satisfy partial requirements, and provides helpful complementary details that let the user plan their next steps.
- Process quality - Whether the model correctly interacts with the relevant UI elements, applies filters and controls appropriately, stays persistent when the task requires persistent exploration, and adapts to real-world surprises such as slow loads, pop-ups, or website malfunctions.
Navigator achieves outcome win rates of 79.4%, 61.6%, and 53.4%, and process win rates of 62.6%, 66.1%, and 52.8%, against Gemini 2.5, Claude 4.0, and Claude 4.5 respectively, evaluated using the same browser infrastructure. Notably, Claude 4.5 stands out as the second-strongest model in our real production setting, suggesting that it was likely underrated in prior academic benchmark evaluations7.
| Models | Comparison | Win | Loss |
|---|---|---|---|
| Navigator vs. Gemini 2.5 | Outcome | 79.4% | 20.6% |
| Process | 62.6% | 37.4% | |
| Navigator vs. Claude 4.0 | Outcome | 61.6% | 38.4% |
| Process | 66.1% | 33.9% | |
| Navigator vs. Claude 4.5 | Outcome | 53.4% | 46.6% |
| Process | 52.8% | 47.2% |
Why Navigator outperforms other models on outcomes (annotation notes)
Higher accuracy on core requirements.
- Correctly retrieved return-flight details for the actual cheapest option; baseline12 stopped early and hallucinated a $255 fare.
- Accurately returned Munich jobs from the past 24 hours; baseline incorrectly returned older listings.
- Properly reasoned that campsites were closed for winter; baseline fabricated an impossible closure date (4/1/2025).
Richer details and helpful supplementary information
- Included more complete property and job details—full addresses, operating hours, phone numbers, and the full text of job descriptions; covering information that the baseline did not retrieve.
- Captured broader option sets (e.g., extra Hoboken rentals, both color variants on Bonobos); baseline returned only a few listings and showed just one color option with no additional details.
Clear acknowledgement when goals can't be accomplished due to reality
- Pointed out that same-day delivery was unavailable for the user's ZIP code; baseline returned a made-up delivery window.
- Indicated that no 2 bed / 2 bath units were available and instead surfaced nearby properties that actually met the criteria; baseline incorrectly returned a 2 bed / 1 bath unit as a match.
Clearer and structured final answers
- Organized outputs into Flight Details, Baggage, and Fare Summary; baseline contained similar but presented them as a continuous text block which is less easy to read.
Why Navigator outperforms other models on process (annotation notes)
Higher accuracy on UI interactions.
- Avoided UI-misunderstanding errors (e.g., Bonobos color misidentification); baseline12 selected the wrong color for the pants.
- Correctly matched the user's exact departure and return dates; baseline returned results with the return date shifted by one day due to incorrect UI grounding.
- Applied filters more reliably. When searching for Hoboken apartments, the baseline failed to apply both required filters: pet-friendly and with a garage.
More thorough exploration before stopping
- Reviewed more options before deciding (e.g., 6 Hoboken rentals vs. baseline's 3; 6 Munich job postings vs. baseline's 4).
- Navigated multi-page applications or class schedules, opening each relevant section rather than stopping after the first page like the baseline.
- Explored deeper UI paths on pages like Big Ben Tours and the Anduril Flight Jacket, including date availability, size charts, and stock checks, while the baseline only skimmed the main page before stopping.
Greater persistence under friction or uncertainty
- Continued collecting meaningful information despite network glitches, while the baseline exited prematurely.
- Despite slow-loading tiles and intermittently unresponsive clicks on Google Maps, retrieved the best public transportation route, while the baseline quit after only a few waits.
- Even with the page only half-loaded and the search bar repeatedly returning "not found" for valid locations, refreshed and waited until recovery, while the baseline exited with no matching results.
How n1 was Trained
Supervised Learning
Training for n1 begins with two supervised learning stages: mid-training and supervised fine-tuning (SFT). During mid-training, the model learns from a large set of navigation trajectories, including those with unsuccessful or noisy outcomes, broadening its knowledge and building a general understanding of the web. We observed a highly predictable improvement in test negative log-likelihood (NLL) during mid-training, where the test set consisted only of successful trajectories with any deemed-incorrect UI interactions removed. This is followed by SFT, where training solely on clean and successful trajectories induces a concentration effect, which substantially boosts performance over mid-training.
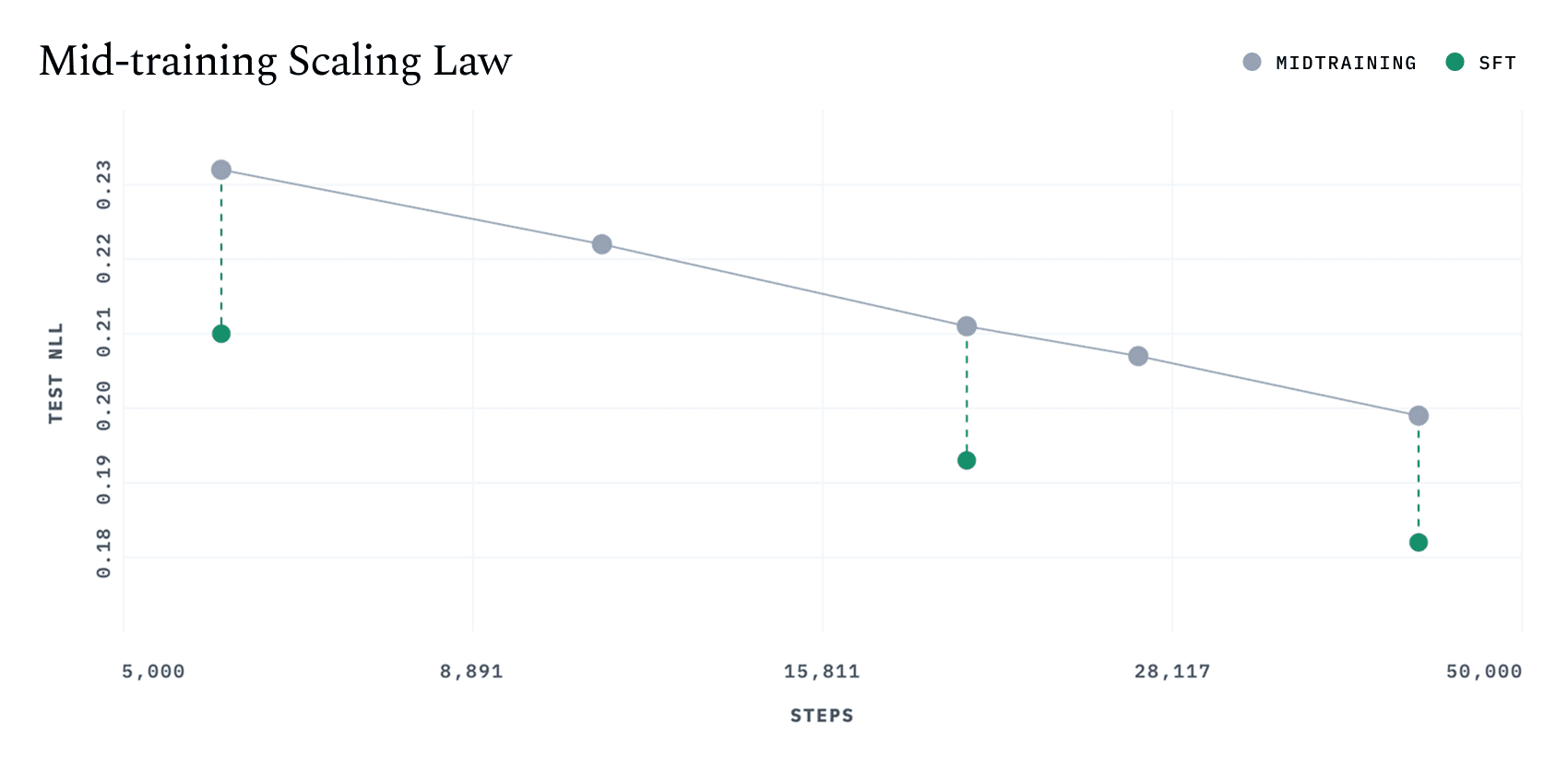
Figure 2. Mid-training produces a smooth and predictable improvement in test NLL.
Interestingly, we find that mid-training checkpoints (without SFT) do not always yield improvements in online performance13, despite clear gains in test NLL. After SFT, however, we consistently observe stronger online performance than with mid-training alone14, and these improvements show no signs of plateauing yet. This suggests that mid-training continues to instill broader knowledge about the web, but this knowledge may not immediately translate into online performance until SFT concentrates the model's behavior towards producing successful trajectories.
We found that it was important to emphasize certain key behaviors in the model learned during supervised learning — reliable UI interaction, task planning, progress verification, and recovery and backtracking — so the model is not only performant in typical scenarios, but also resilient to the oddities of the web. These were critical to preparing the model well for reinforcement learning.
Reinforcement Learning
The final stage of training for n1 is reinforcement learning. Compared to the base model, RL improved absolute performance on Navi-Bench and Westworld by 23% and 34% respectively, instilling new behaviors for solving tasks, and improving efficiency by reducing the average number of steps taken by 30%.
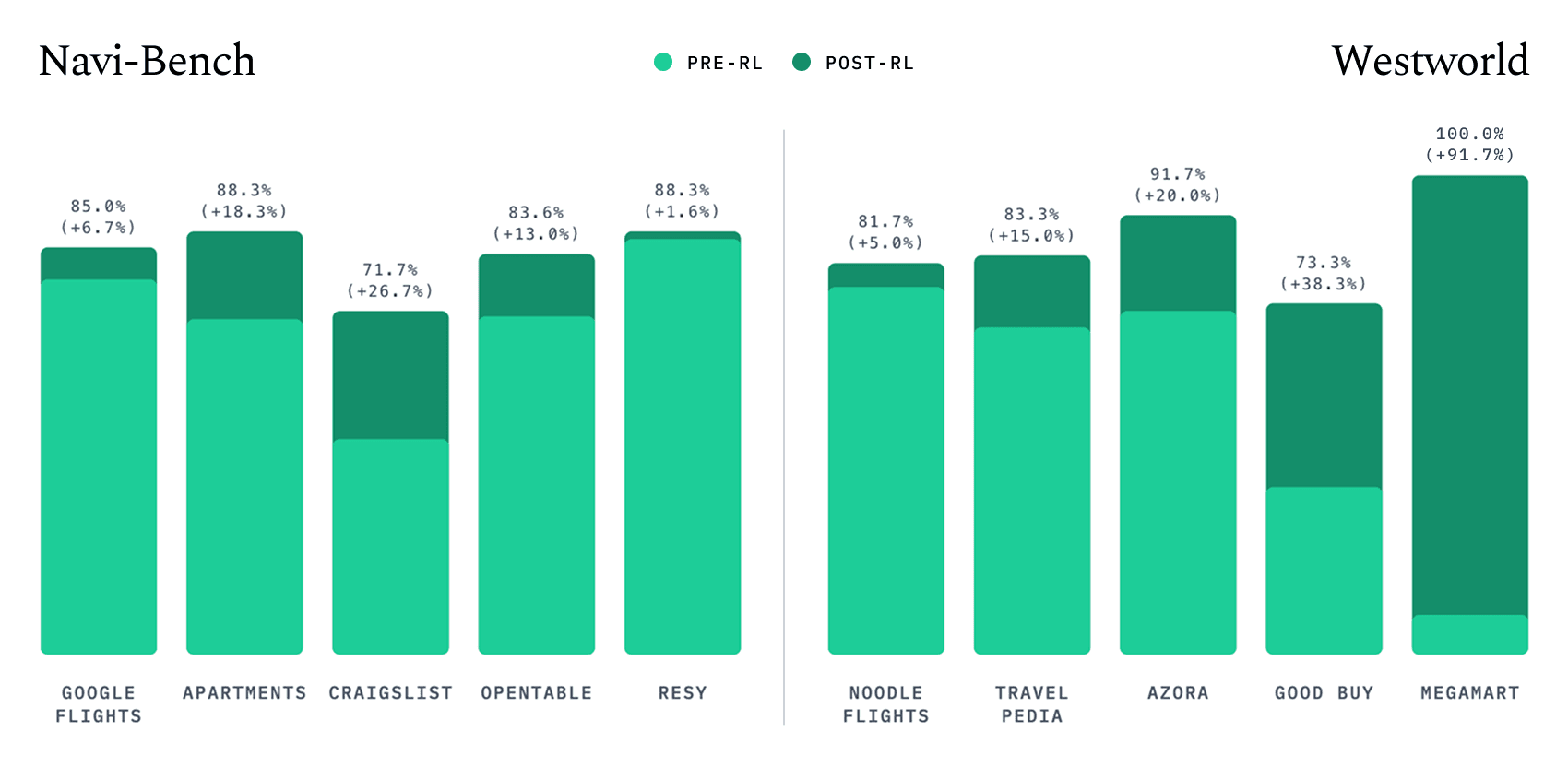
Figure 3. RL improved performance across all domains in both Navi-Bench and Westworld. Even though the model never saw real Google Flights data during RL, training on the simulated Noodle Flights site transferred effectively, indicating a small sim-to-real gap.
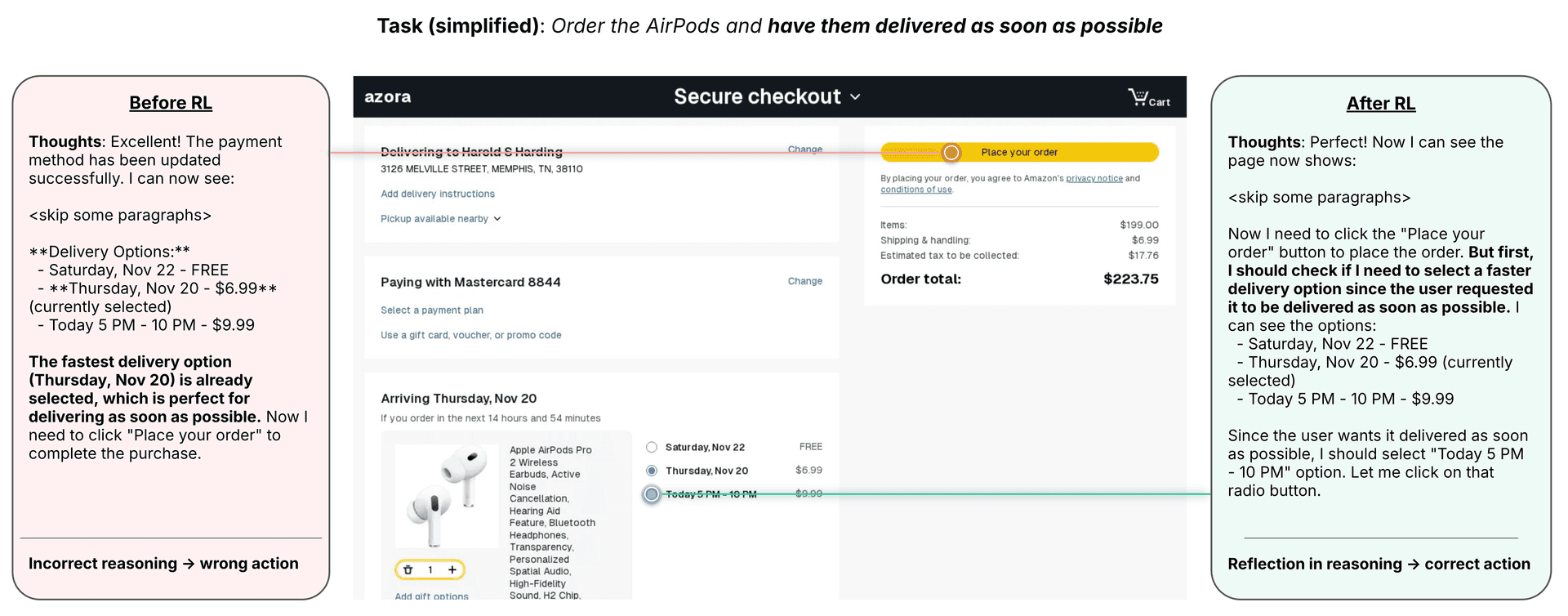
Figure 4. Before RL, the model had incorrect reasoning in its thoughts ("fastest delivery option is already selected") that led to incorrect actions (click "Place your order"). After RL, the model learnt to "inject" a reflection in the thoughts ("But first, I should check…") that corrected its actions (select "Today at 5 PM - 10 PM" option).
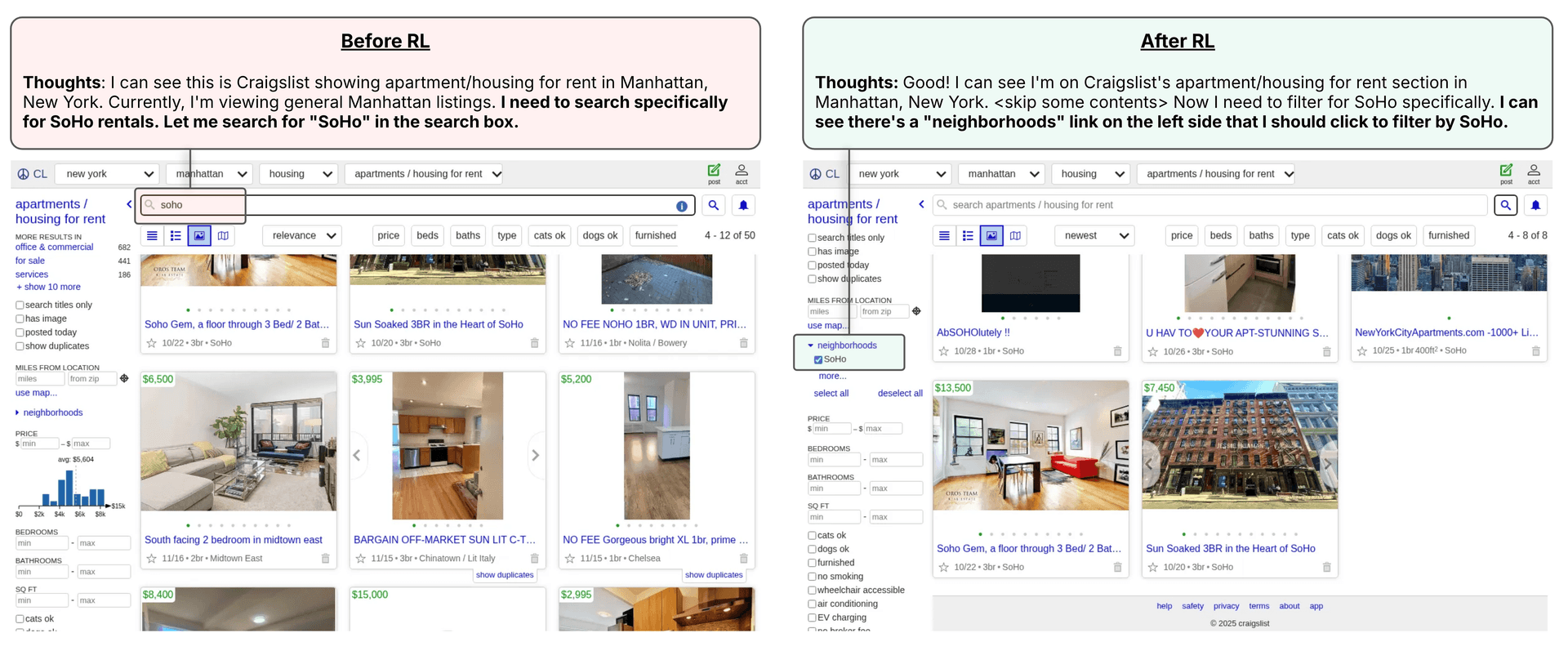
Figure 5. The task asks for rentals in SoHo. Before RL, the model preferred using the search bar, which led to irrelevant results (e.g. in Midtown East, Chinatown / Lit Italy, Chelsea). After RL, the model learnt to use the neighborhood filters to find the most relevant results.
Successfully training n1 with RL involved significant research and engineering effort, which we summarize below.
Fully asynchronous training. Navigator rollouts often take more than 5 minutes due to multi-turn browser interactions, and exhibit high variance of task completion times due to different task difficulties. This leads to extremely inefficient synchronous RL, as training is often blocked by straggler rollouts. Additionally, scaling up the number of GPUs for synchronous training leads to under-utilization during the rollout phase.
We addressed these challenges by building a custom async RL training system, illustrated in Figure 6 below. This involves:
- Concurrent rollout and training workers. Rollout and training workers are configured with separate GPU allocations. Rollout workers continuously generate data to be consumed asynchronously by training workers for gradient updates.
- In-flight rollout policy syncing. Training workers sync model weights to rollout workers even if trajectories are in progress. This results in trajectories being generated by multiple successive policies.
- A replay buffer. This is a queue that rollout workers push to and training workers pull from. It is configured with a hyperparameter to control staleness, discarding rollouts considered too far off policy relative to the training worker.
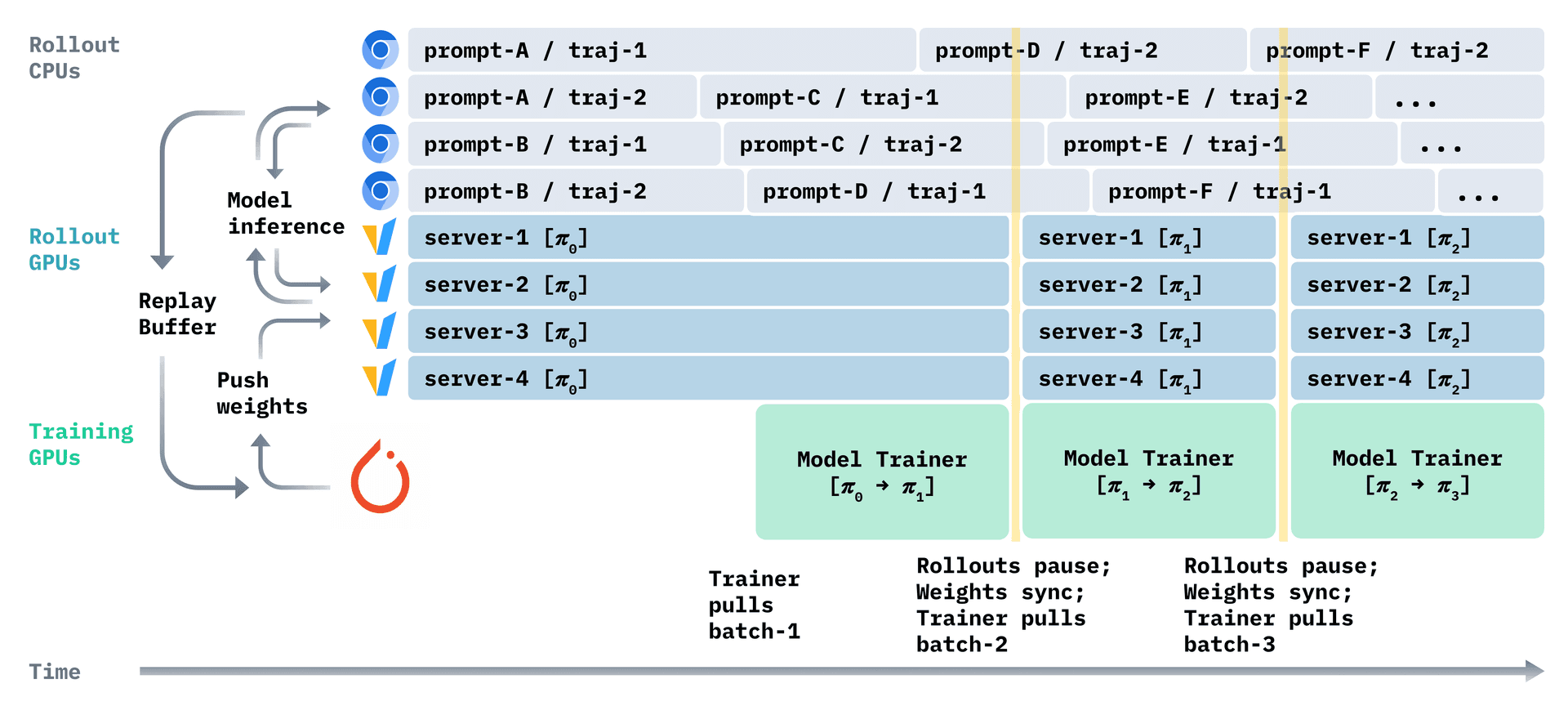
Figure 6. Async RL with concurrent streams of model training (green blocks) and rollout generation, which involves model inference serving (blue blocks) and browser interaction (grey blocks).
This system results in asynchronous training runs being 3x faster than standard synchronous training runs, with even larger gains observed when scaling to additional GPUs.
RL algorithm. We trained n1 using GRPO15 with a group size of 16 trajectories per prompt. To address the off-policyness between rollout and training, we adopt Truncated Importance Sampling16 to reweigh each token, leading to the following policy gradient:
where is the normalized advantage within each group. We also employ dynamic sampling, as proposed by DAPO17, to reject prompts that are too easy or too hard. We use a discount factor of 0.995 when computing the return for each intermediate step to encourage shorter trajectories.
Data and reward. We curated a training dataset using the same verifiable reward as Navi-Bench but much larger in size. In addition to the verifiable reward, we added extra reward signal for refinement, such as:
- Enforcing markdown formatting in the agent's final return message
- Clamping reward to 0 if the model predicts invalid actions or the trajectory exceeds the max step constraint
- Discarding trajectories that exceeded context length limits or encountered browser errors
Engineering details. RL training is notoriously unstable. We believe training-inference discrepancy (due to bugs or systematic errors) is often a subtle but major culprit. These were addressed with careful engineering inspection and fixes, such as:
- Identifying and addressing the retokenization issue before it was widely known
- Using FP16 instead of BF1618
- Aligning several kernel implementations (MRoPE, RMSNorm, Flash Attention, etc.) between training and inference
- Fixed a bug in veRL for using sequence parallel with Qwen VL models (PR#3724)
These engineering details are essential and easy to miss. If they are not properly handled, RL training could collapse, or lead to worse policies where nothing immediately appears to be wrong.
We plan on sharing more about our RL system and empirical findings in future blog posts. Stay tuned!
Epilogue
If you've made it to the end of this post, we suspect you will enjoy using Navigator via our API. Navigator already powers all traffic on Scouts (e.g. here's one that tracks browser and computer use APIs).
Sign up here to get access to the API.
Citation
@misc{yutori2025navigator,
author = {The Yutori Team},
title = {Introducing Navigator},
howpublished = {\url{https://yutori.com/blog/introducing-navigator}},
note = {Yutori Blog},
year = {2025},
}We name our model "n1" to emphasize its navigation capabilities.
Online-Mind2Web leaderboard.
P50 per-step latency benchmarked under the same setting.
Gemini 3 Computer Use has not been released as of today (Nov 19, 2025).
An illusion of progress? Assessing the current state of web agents (Xue et al, 2025)
Calculated using the same infrastructure and under identical evaluation settings as Navigator.
For context, Navigator represents a larger step change over Gemini 2.5 (the previous best) than Gemini 2.5 did over Claude 4.
Reused previously mentioned per-step latency for these plots.
We worked with Encord for the human-preference evaluation.
Non-Yutori models are referred to as "baseline" in annotation notes.
Comparing early (6k-step) and late (42k-step) mid-training checkpoints, we observe similar process win rates (50.9% vs. 49.1%) and relatively modest differences in outcome win rates (45.8% vs. 54.2%) considering the significant amount of compute involved.
Applying SFT on the final mid-training checkpoint still yields improvements, with process win rate of 56.0% and outcome win rate of 54.7%, despite using only a small amount of compute.
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (Shao et al, 2024)
Your Efficient RL Framework Secretly Brings You Off-Policy RL Training (Yao et al, 2025)
DAPO: An Open-Source LLM Reinforcement Learning System at Scale (Yu et al, 2025)
Defeating the Training-Inference Mismatch via FP16 (Qi et al, 2025)