The bitter lesson for web agents
Today's AI web agents are divided between text-only agents that ingest the DOM of webpages, and computer-use agents that ingest webpages visually. Most currently deployed AI web agents rely on the former approach.
However, we have found that agents that take actions on the web the way that humans do — using vision — generalize better than agents that take actions based on the DOM, because the web is implemented in a Cambrian Explosion's worth of diverse ways.
Single-Page Applications
What was the final score of this game between the Minnesota Timberwolves and the Brooklyn Nets on nba.com?
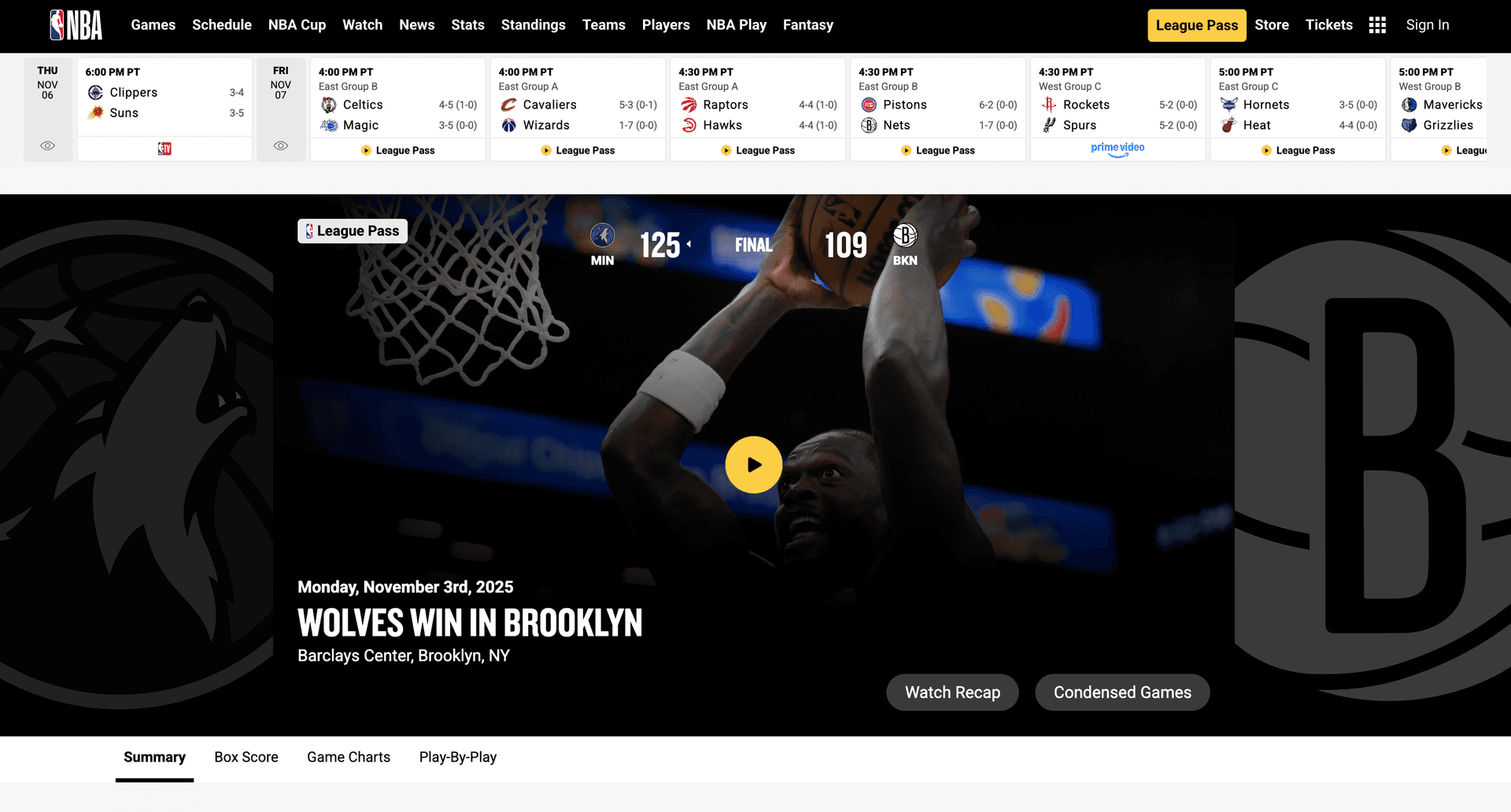
Upon the initial pageload, the score doesn't exist in the HTML — just a placeholder:
<div class="ScoreStripGameSkeleton_gameContainer__bcST2"
data-testid="score-strip-skeleton">
<!-- Empty placeholder that shows loading UI -->
</div>then, a couple hundred milliseconds after pageload, the website kicks off an AJAX API call that gets the score itself:
URL: https://cdn.nba.com/static/json/liveData/scoreboard/todaysScoreboard_00.json
Method: GET
Headers:
- sec-ch-ua-platform: "your-operating-system"
- referer: https://www.nba.com/
- user-agent: Mozilla/5.0...
Response Headers:
- cache-control: max-age=10 (10-second cache)
- content-type: text/plain
- etag: "095a50e57d2dcd757c2c6ea63d5c71c5"
- last-modified: Tue, 04 Nov 2025 23:03:16 GMT
Response Body Structure:
{
"meta": {
"version": 1,
"time": "2025-04-01 06:03:15.315",
"code": 200
},
"scoreboard": {
"gameDate": "2025-11-04",
"leagueId": "00",
"games": [
{
"gameId": "0022500156",
"gameStatus": 3,
"period": 4,
"gameClock": "",
"homeTeam": {
"teamId": 1610612751,
"teamTricode": "BKN",
"score": 109,
"periods": [
{"period": 1, "score": 28},
{"period": 2, "score": 31},
{"period": 3, "score": 29},
{"period": 4, "score": 21}
]
},
"awayTeam": {
"teamId": 1610612750,
"teamTricode": "MIN",
"score": 125,
"periods": [...]
}
}
]
}
}If you were to ingest just the HTML as returned by the initial GET request, you would not be able to tell what the final score was. Because this page on nba.com is a React single-page application, you need to wait for AJAX.
To handle this page properly, you'd need to perform a pageload → wait for AJAX → freeze the DOM as it exists. However, this opens the door to more parsing problems down the line.
Native Rendering
Here's another example, drawn from a query to Scouts, Yutori's web monitoring agent product.
Is the 25.4mm osmium cube on this website in stock or out of stock at the moment?
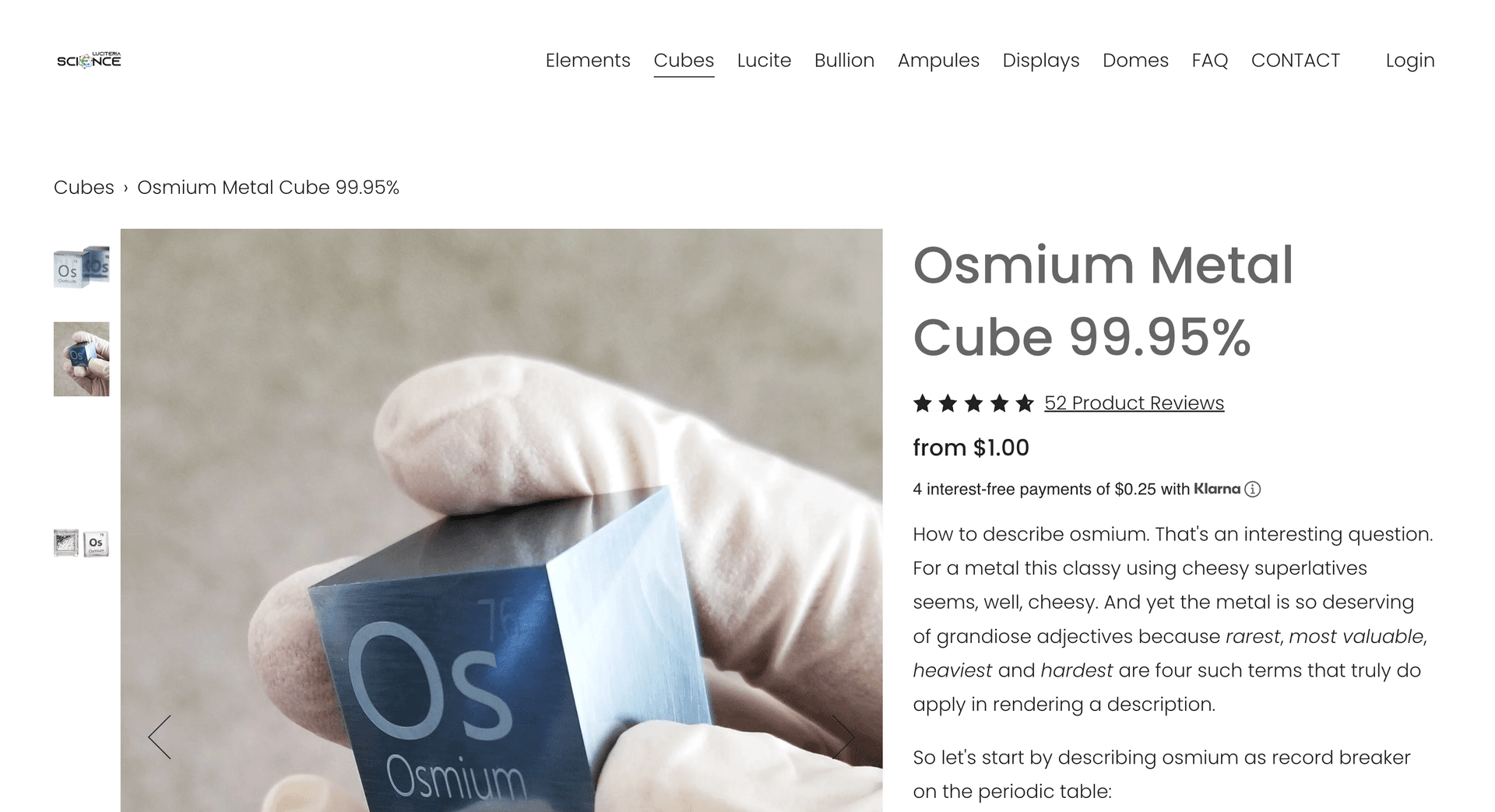
If you visit the webpage yourself to test, you'll find that, as of the time of writing, the 25.4mm osmium cube appears to be sold out.

Unlike in the prior example, this time the answer is actually baked into the HTML at pageload, sort of! The provided URL is a Squarespace site, and Squarespace server-side renders a large JSON window.Static.SQUARESPACE_CONTEXT snippet that is served to the user upfront.
"product": {
"variants": [
{
"sku": "Os10.1mm_empty",
"stock": {"unlimited": false, "quantity": 0},
"attributes": {"Size": "Empty labeled 10mm box"}
},
{
"sku": "Os10.1mm_1g",
"stock": {"unlimited": false, "quantity": 10},
"attributes": {"Size": "10mm box with 1g crystalline powder"}
},
{
"sku": "Os10mm",
"stock": {"unlimited": false, "quantity": 0},
"attributes": {"Size": "10mm Metal Cube"}
},
{
"sku": "Os25.4mm",
"stock": {"unlimited": false, "quantity": 0}, // Out of stock!
"attributes": {"Size": "25.4mm Metal Cube"}
}
]
}The approach that you would have needed to have taken to solve the nba.com example breaks this site, because the "Sold Out" selector is rendered natively based on scripts. Then at pageload, the item selector just looks like this:
<select name="variant-option-Size-select">
<option class="unselected-option-value" value="">
Select Size
</option>
<option value="Empty labeled 10mm box">
Empty labeled 10mm box
</option>
<option value="10mm box with 1g crystalline powder">
10mm box with 1g crystalline powder
</option>
<option value="10mm Metal Cube">
10mm Metal Cube
</option>
<option value="25.4mm Metal Cube">
25.4mm Metal Cube
</option>
</select>As a result, ChatGPT, which handles React sites just fine, has no way of seeing that the product is sold out:
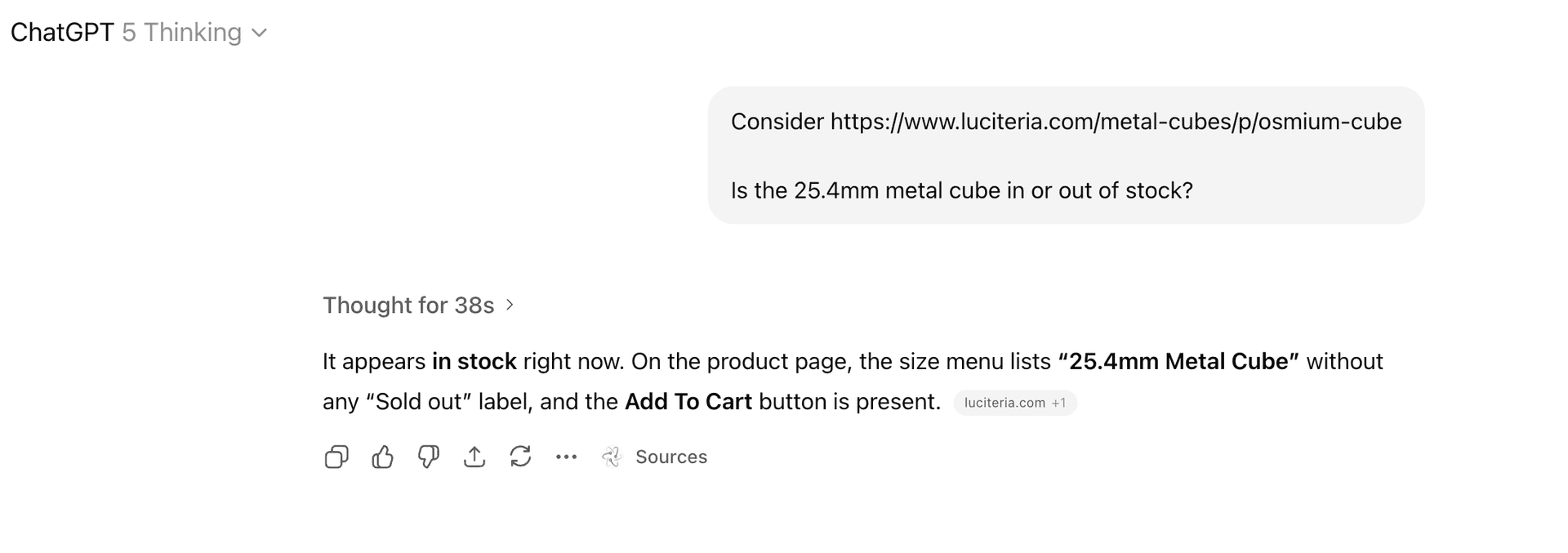
In this case, in order for a text-only agent to answer this question, it must reason over the full content fetched from the initial pageload, including the scripts that contain the answer — or just look at the page visually, like a human would. In practice, to reliably get both answers correct, vision ends up being the simplest approach.
Token Costs and the Difficulty of DOM Parsing
Ingesting the DOM is very token-expensive too. For example, we sampled 250 URLs randomly across all Scouts trajectories, fetched the full DOM for each URL, and calculated the number of tokens required to represent each DOM using the GPT-5 tokenizer via OpenAI's tiktoken library. The results are as follows:
Total tokens: 39,614,147 across 250 pages
Average: 158,457 tokens per page
Median (p50): 82,582 tokens
p75: 207,313 tokens
p90: 426,464 tokens
p95: 589,181 tokens
Max: 962,933 tokensThe average Scout performs about 115 unique webpage interactions per day on your behalf, so in order to do all of these with perfect fidelity, we would need to consume ~18 million tokens per day per Scout just to interact with the web! So, to make DOM-based methods work efficiently, we would need to parse out task-relevant sections from the webpage. However, this creates its own set of problems.
Suppose you were to filter the DOM to try and show your agent only the clickable elements on the page. One commonly-used library for building DOM agents uses a few heuristics to detect interactive elements: it checks (1) semantic HTML tags like <button> and <a>, (2) explicit event handler attributes like onclick and tabindex, (3) ARIA roles and accessibility tree properties, and finally (4) visual affordances like cursor: pointer styling. This works great for the majority of sites, but can also fail sometimes. For instance:
Suppose you wanted to get the BibTeX citation for this ArXiV page.

ArXiv's "Export BibTeX Citation" button is not marked as clickable by the script, because it's implemented as a <span> instead of as a <button> or <a>.
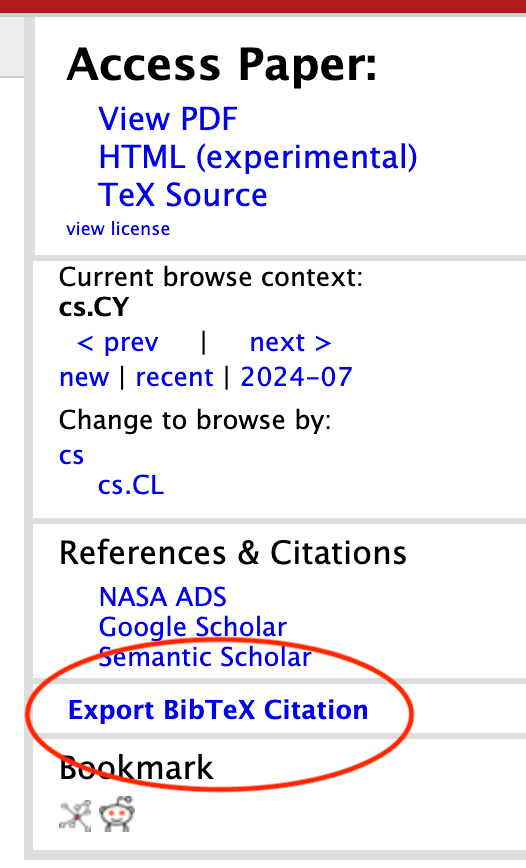
Why the script misses it:
- Tag span not in interactive_tags
- No onclick handler
- No ARIA role attribute
- cursor:pointer only on :hover/:focus states, NOT in default statespan.bib-cite-button:hover, span.bib-cite-button:focus {cursor: pointer; }
Why is this button a span element whereas the others above are a elements? Impossible to say — but if you scale up your web agents enough, sooner or later you'll run into a rabbit hole of failure modes like these that are too odd to anticipate.
DOM vs Visual Outliers
Many websites are simply implemented in weirder ways than they seem visually. For instance, we randomly sampled 250 websites from across all Scouts trajectories, and ran equivalent representations of each site — full-page DOM and full-page screenshot — through a long-context, multimodal embedding model (Cohere Embed v4.) The average Euclidean distance of a website to its 10 nearest neighbors then serves as a measure of uniqueness — the larger the distance, the more of an outlier the website is in the space of websites. Interestingly, the sites with the weirdest DOMs are not the sites that are weirdest visually. In fact, none of the 20 biggest DOM outliers are particularly great screenshot outliers:
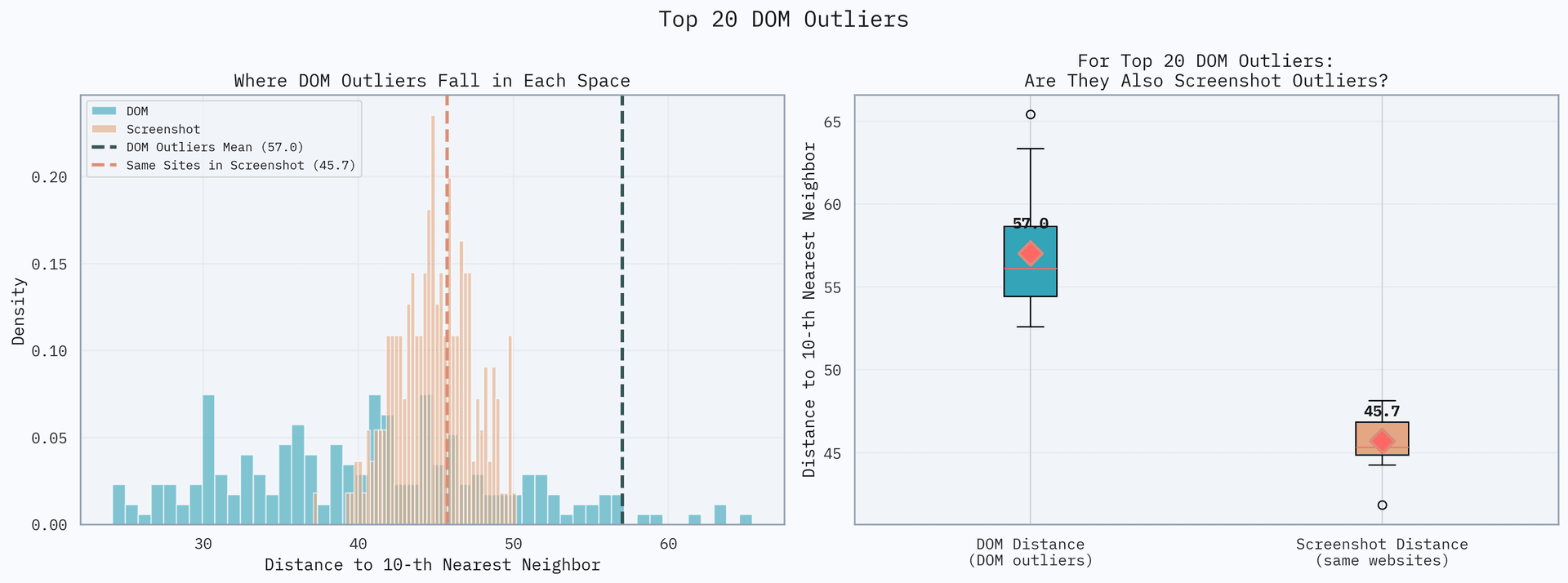
Why should this be so? Consider the underlying diversity in web implementation: websites with similar visual appearance and functionality can have radically different DOM structures depending on the framework, CMS, or template used. Two e-commerce sites might look nearly identical visually but differ dramatically in their HTML structure — one using React with client-side rendering, another using server-side PHP with traditional templates.
Some examples from among the 20 biggest outliers:
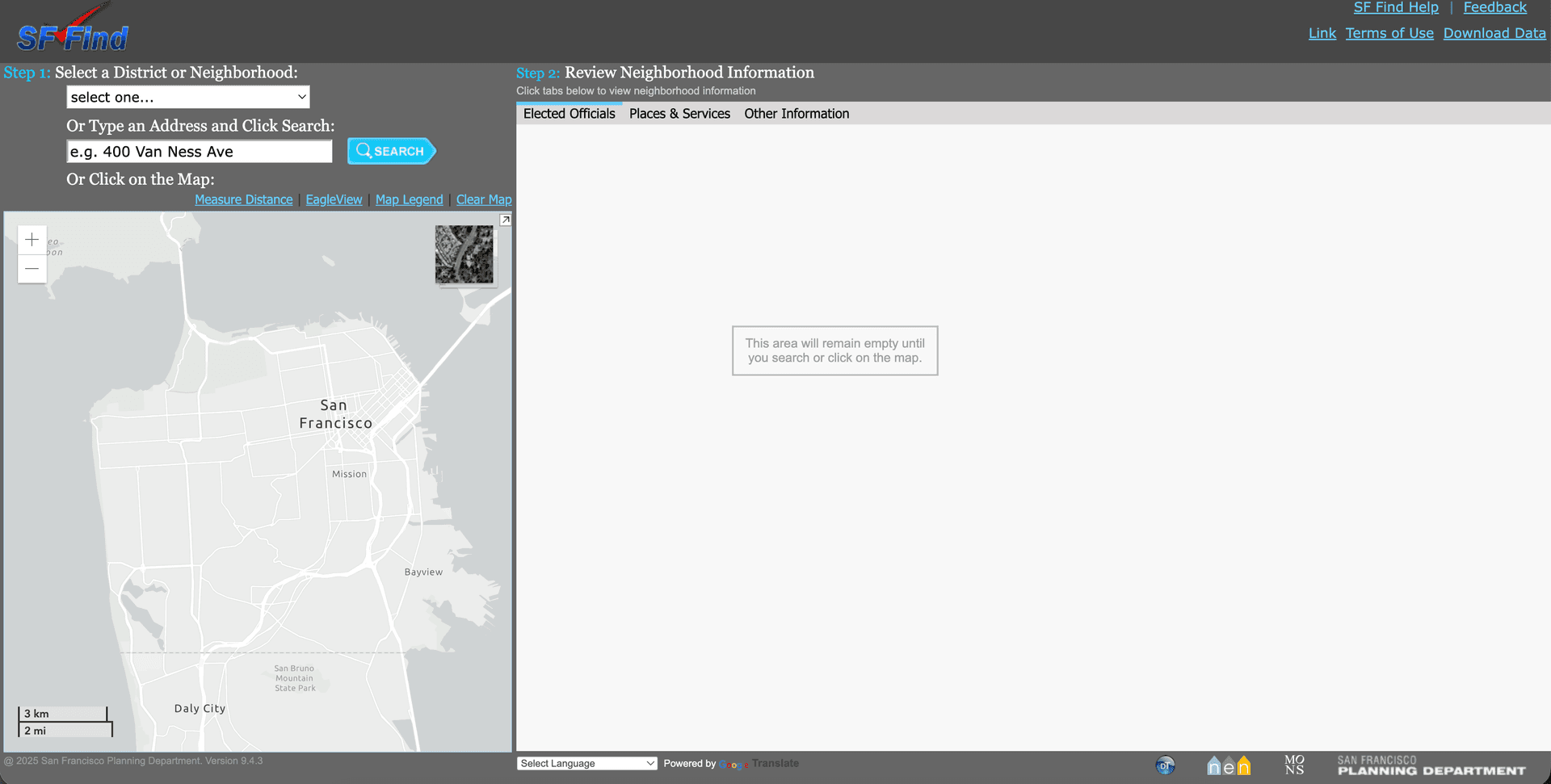
The SF Planning Department's GIS tool
The entire site is implemented in one large block of Javascript, with many lines of commented out code present. DOM agents can't view the map, because it's implemented as a canvas element!

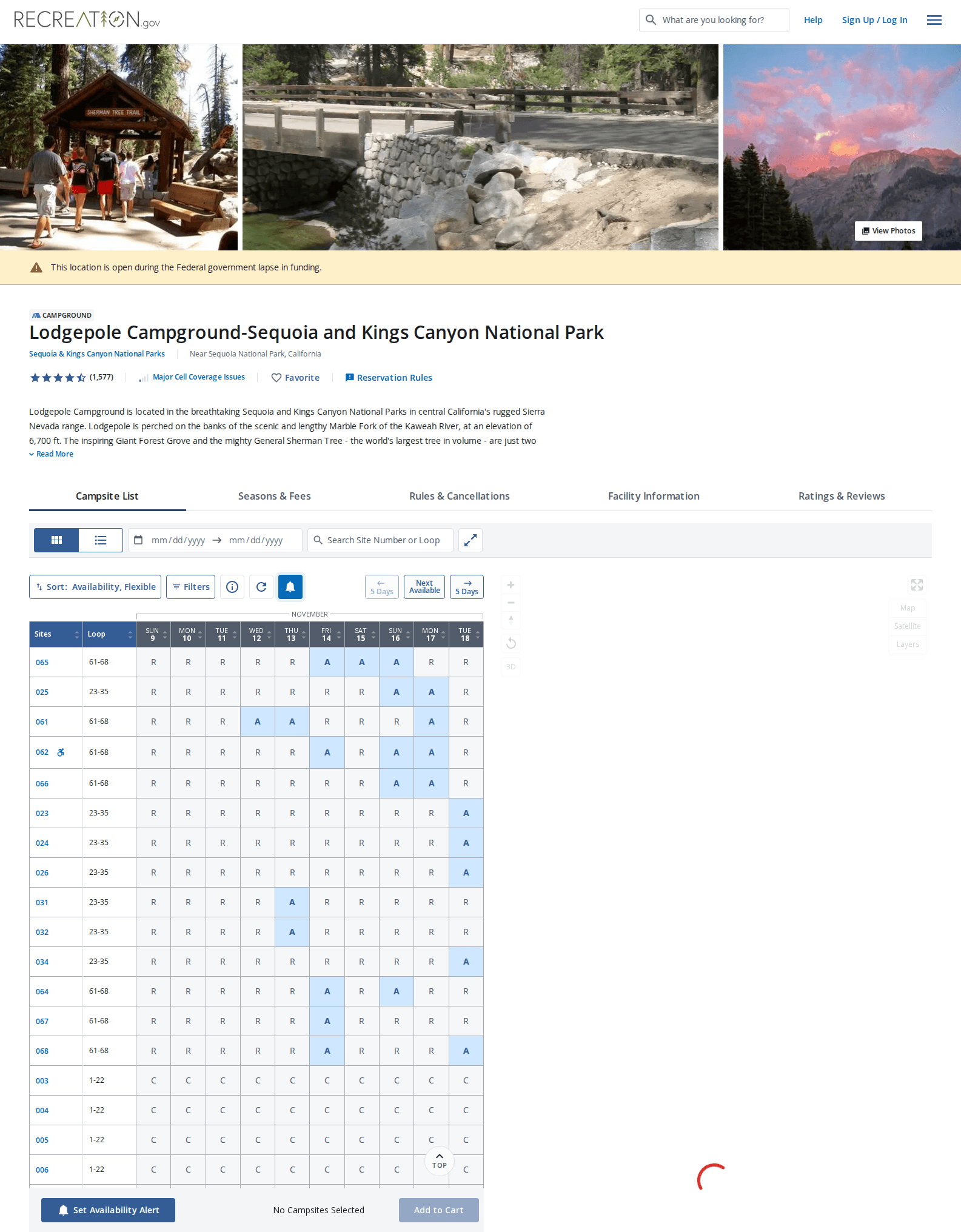
A campground reservation page for Sequoia National Park
Server-side renders a duplicate version of the page for screen readers, which is then hidden from screen readers
Conclusion
In principle, building web agents that utilize the greater structure of the DOM sounds promising. It has all the same information as is presented to the user visually, and you can sometimes use that structure to accomplish domain-specific tasks more efficiently. But because it takes up a lot of tokens, and because the web remains largely designed for human consumption at the end of the day, it tends to be more generalizable if you just navigate the web the way humans do.
Further, while you can always fix e.g. parsing edge cases or specific sites' oddities in a one-off fashion, doing this reduces the generality of your agent harness and impedes learning at scale. If you want to benefit from advances in search and learning capabilities, it's much better for your agent to interact with the world in a consistent way.
The weirdness of the DOM is perhaps part of why the web requires so much interaction from users. Under the hood, it's a tangled mess that doesn't lend itself to automation — so in order to find anything useful, valuable, or interesting, users must pay a subscription fee denominated in clicks, scrolls, and hovers.
This is the Dead Internet hiding in plain sight: there is nothing worth having on the internet that doesn't require spending attention as currency. In a sense, the entire web is one continuous Turing test.
That's why we're building Yutori — we believe the internet can be radically unhobbled by machines that pay attention on your behalf. We are building an internet that is post-scarcity for the things that matter to you, and post-abundance for distractions. If that vision resonates with you, consider joining the waitlist for Scouts.